

31 juillet 2026
 5 min
5 min

Bienvenue sur LeFil.vet
L'accès au site web nécessite d'être identifié.
Merci de saisir vos identifiants de connexion.
Indiquez votre email dans le champ ci-dessous.
Vous recevrez un email avec vos identifiants de connexion.
3 août 2026
Strongles équins : la mise à jour des niveaux de résistance révèle « un besoin urgent de changement réglementaire »
par Vincent Dedet
4 min

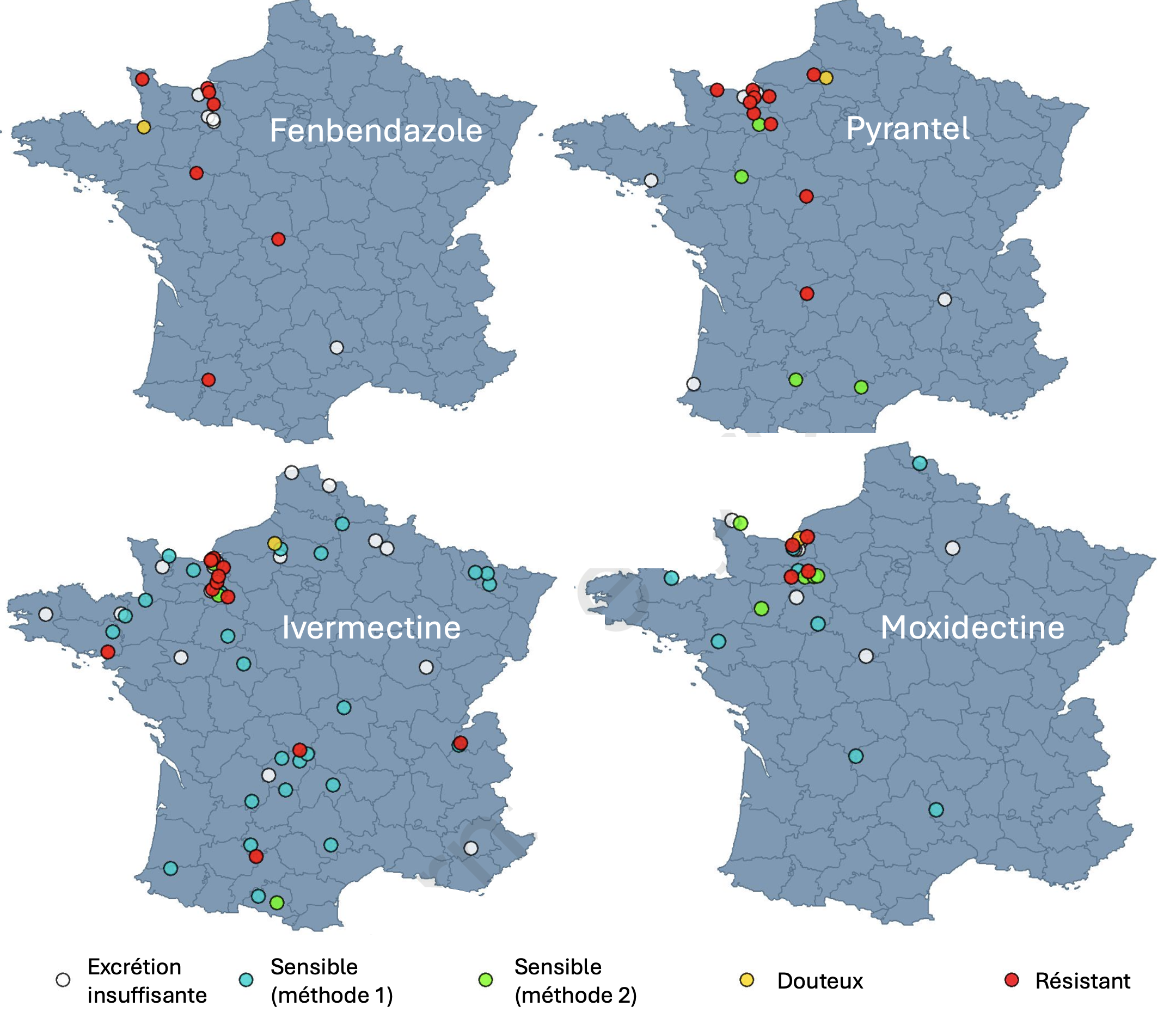
Les strongles équins en France présentent des résistances aux quatre molécules anthelminthiques disponibles : fenbendazole, pyrantel, ivermectine et moxidectine. Les niveaux de résistance et leur diffusion, détectés dans une étude publiée fin juillet font écrire aux chercheurs de l'Anses-Goustranville et de l'Institut français du cheval et de l'équitation (IFCE) que cela met en lumière « l'urgence de modifier la réglementation afin d'exiger l'utilisation d'anthelminthiques uniquement après une évaluation diagnostique (par exemple, un traitement sélectif ciblé reposant sur les résultats de coprologies) afin de réduire la pression de sélection exercée sur les populations de parasites ».
« En France, la plupart des études évaluant l'efficacité des anthelminthiques (AH) contre les strongles [des chevaux] ont été réalisées il y a 9 à 15 ans. Elles ont mis en évidence une résistance généralisée au fenbendazole (FBZ) et quelques signes de résistance au pyrantel (PYR) », expliquent les auteurs. Pour disposer de données actualisées, ils ont donc sollicité des structures équines en France hexagonale via différents canaux de sensibilisation (compétitions, contact téléphonique d'éleveurs, science collaborative…) entre juillet 2022 et septembre 2023. Étaient incluses celles disposant d'au moins 5 animaux en groupe paissant ensemble, n'ayant pas administré d'AH dans les deux mois précédents, et conservant ces animaux ensemble pendant la durée de l'étude. Les structures incluses devaient administrer le traitement AH (pâtes orales, l'une des 4 molécules disponibles) et respecter le protocole du test standard d'évaluation de la résistance : le test de réduction de l'excrétion fécale (FECRT). Les coprologies étaient réalisées sur des prélèvements individuels de crottins réalisés la veille ou le jour de l'administration du traitement et 14 jours plus tard. Les essais FECRT ont été réalisés entre 2022 et 2025.
Les 95 structures qui ont participé à l'étude sont avant tout localisées en Normandie (44 %), Nouvelle-Aquitaine (12 %) et Pays-de-la-Loire (9 %). Les élevages représentaient un peu moins de deux structures sur trois (62/95), devant les centres équestres (21/95). Les structures participantes comprenaient de 1 à 6 groupes de chevaux (des essais ont été réalisés sur 140 groupes, soit 1 046 chevaux). Toutefois, seuls les résultats de 104 FECRT ont pu être exploités, correspondant à 98 groupes : pour un quart (26 %) des structures participantes, l'efficacité du traitement AH n'a pas pu être évaluée. Dans 58 des structures participantes, des FECRT ont été réalisés avec une molécule (population résistante pour une structure sur deux), dans 10 autres, deux molécules ont été testées (une structure avec une population résistante aux deux AH) et trois des molécules ont été testées dans deux autres (une structure avec une population triple résistante). Ainsi (voir l'illustration principale) :
Lorsqu'ils réalisent une analyse des facteurs de risque significatifs de la présence d'une résistance, les auteurs observent en premier lieu la géographie (le fait d'être implanté hors de Normandie est associé à 30 % de protection), et en second lieu les races : le fait de ne pas héberger que des purs sang est associé à 89 % de protection.
Plusieurs recommandations clôturent cette publication. En premier lieu, au vu du niveau très élevé de résistance au FBZ alors que cette molécule est « encore utilisée par 57 % des éleveurs français pour les équidés de plus d'un an », il paraît « pertinent de réévaluer l'intérêt de cette molécule pour le traitement des strongyloïdoses ». En second lieu, le fait que des résistances soient mises en évidence au regard de toutes les molécules disponibles en France « souligne l'urgence de rationaliser l'utilisation des traitements antiparasitaires en mettant en œuvre des stratégies de traitement sélectif qui maintiennent une population de strongles dans des zones refuges et réduisent la pression de sélection », qui ne sont appliquées que par 5 % des détenteurs d'équidés en France. Les auteurs précisent d'ailleurs qu'au Danemark et en Suède, « le traitement sélectif reposant sur l'examen coprologique est soutenu par la législation depuis 1999 et 2007, respectivement ». Ils prennent donc note, en troisième lieu, que les avertissements et recommandations émis par la communauté scientifique au cours de la dernière décennie « n'ont pas suffi à modifier les pratiques des vétérinaires et des éleveurs. Une action réglementaire apparaît désormais comme le seul moyen d'induire un changement durable des pratiques » antiparasitaires.
31 juillet 2026
5 min
30 juillet 2026
4 min

28 juillet 2026
4 min
27 juillet 2026
6 min
24 juillet 2026
6 min
